
business resources
Alibaba Cloud Releases Advanced TTS Model With Free 1M-Character Access
Qwen3-TTS
09 Dec 2025

Alibaba has launched Qwen3-TTS, a zero-shot, multilingual text-to-speech model with 49 voices, support for 10 languages and 9 Chinese dialects, and a 48 kHz output. It delivers industry-leading accuracy with a WER of 2.8% (English) and 1.9% (Chinese). Developers get 1 million free characters monthly, with voice cloning coming in Q1 2025.
Alibaba has introduced Qwen3-TTS, the newest addition to the Qwen3 model lineup, bringing forward text-to-speech capabilities built around zero-shot generation, multi-voice options, and cross-language support. The model is now accessible through the Alibaba Cloud console, where developers can try it with up to one million free characters each month.
49 built-in voices with instant switching
Qwen3-TTS comes with 49 professionally designed voices, ranging from youthful tones to dialect-speaking characters. These voices are designed for various use cases such as narration, online teaching, customer support, and livestreaming. The model supports 10 major languages as well as 9 Chinese dialects, including Cantonese, Sichuanese, and Northeastern Mandarin, and can shift between different roles for the same text without any retraining.
Natural speech through tone and rhythm modelling
To generate more lifelike audio, the system combines an autoregressive acoustic model with a prosody prediction module capable of adjusting intonation, inserting pauses, and interpreting emotional tags. Output is produced at a 48 kHz sampling rate, achieving a MOS score of 4.53, noticeably higher than the typical industry performance.
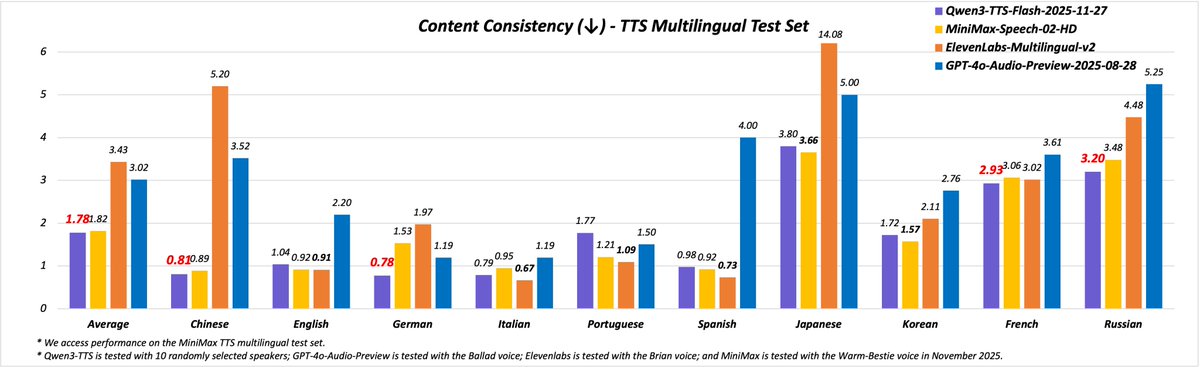
WER performance surpassing leading commercial engines
In multilingual benchmark tests (MLS and Common Voice), Qwen3-TTS achieved a 2.8% English word error rate and 1.9% Chinese word error rate, improving on Azure TTS results by 18% and 24%, respectively. These results set a new open-source standard for speech synthesis accuracy.
Use in education: zero-shot reading assistance
Alibaba Cloud has launched a “One-click Read” feature that allows teachers to upload PowerPoint slides and automatically generate dialect-based audio explanations. This tool has already been tested in 120 schools in Shanghai, helping students learn pronunciation through voices that sound closer to their local speech patterns.
Pricing and access
Free plan: 1 million characters per month, unlimited access to all 49 voices
Paid plan: 0.8 RMB per 10,000 characters, with SSML and real-time streaming
Available via: console.aliyun.com → Artificial Intelligence → Speech Synthesis → Qwen3-TTS
What’s coming next
Alibaba plans to release a 10-second voice cloning API in Q1 2025, enabling users to create personalised voices from short audio samples. An 80 kHz ultra-high-fidelity version is also expected, targeting podcasters, audiobook production, and virtual creators.
Industry perspective
The text-to-speech market is shifting from basic intelligibility toward personalised, expressive voice generation. Qwen3-TTS positions itself as a strong alternative to services from AWS and Azure by offering open-source accessibility, lower costs, and powerful zero-shot performance. With upcoming voice cloning and higher-resolution models, speech generation may move into an era where every user can craft their own customised digital narrator. AIbase will continue monitoring the rollout of these new features and their commercial adoption.






