
citiesabc, first_page
Turing Award Winner Yann LeCun Raises $1 Billion to Challenge the Dominance of Large Language Models
16 Mar 2026

With Advanced Machine Intelligence (AMI) Labs now valued at $3.5 billion, LeCun is betting that the future of AI lies not in predicting the next word but in understanding the physical world the way humans do.
The artificial intelligence industry has coalesced around one dominant paradigm: large language models (LLMs) that predict the next token in a sequence. For Yann LeCun, one of the most decorated figures in AI research, this is precisely the problem. The Turing Award winner and longtime Chief AI Scientist at Meta has now put over a billion dollars behind his conviction that the field is heading in the wrong direction.
AMI Labs, LeCun's new venture, closed a $1.03 billion funding round at a $3.5 billion valuation. The company's mission: build AI systems capable of learning directly from continuous physical reality, not from vast libraries of text.
There is this herd effect where everyone in Silicon Valley has to work on the same thing. It does not leave much room for other approaches that may be much more promising in the long term.
— Yann LeCun, speaking to The New York Times, January 2026
The mathematical limits of next-token prediction
At the heart of LeCun's critique is a fundamental architectural limitation. Today's leading AI systems use autoregression: the model predicts each next token based on everything that came before it. For language, which is discrete and rule-bound, this works remarkably well. But applied to long reasoning chains or the physical world, the approach breaks down.
Because these models sample from a probability distribution at every step, a single early error shifts the context and causes all subsequent predictions to compound diverge. Hallucinations, in this view, are not a fixable bug but a structural inevitability. As LeCun noted on X in September 2024,
Pure Auto-Regressive LLMs are a dead end on the way towards human-level AI.

Beyond text, the problems are even starker. The physical world produces continuous, noisy, high-dimensional data that a discrete token system cannot cleanly represent. Generative models also waste enormous compute attempting to reconstruct irrelevant background detail — predicting the precise movement of a falling leaf rather than understanding the wind's underlying physics.
JEPA: Learning concepts, not pixels
AMI Labs is built around the Joint Embedding Predictive Architecture (JEPA), a framework LeCun proposed in 2022. Rather than reconstructing raw inputs, every pixel, every word, JEPA works in compressed abstract space.

Two encoders translate raw observations into low-dimensional mathematical representations called embeddings. The system then predicts the future embedding from the current context, learning the salient rules of physics, spatial reasoning, and cause-and-effect without spending any compute on perfectly reproducing reality's surface-level noise.
The JEPA family : architecture evolution
- V-JEPA: Learned physical world modelling purely from watching videos, with no labels or text supervision.
- V-JEPA 2: Enabled zero-shot deployment on physical robots for object picking and placing, requiring minimal training data.
- C-JEPA: The latest iteration, specifically designed to model causal relationships between objects in a scene.
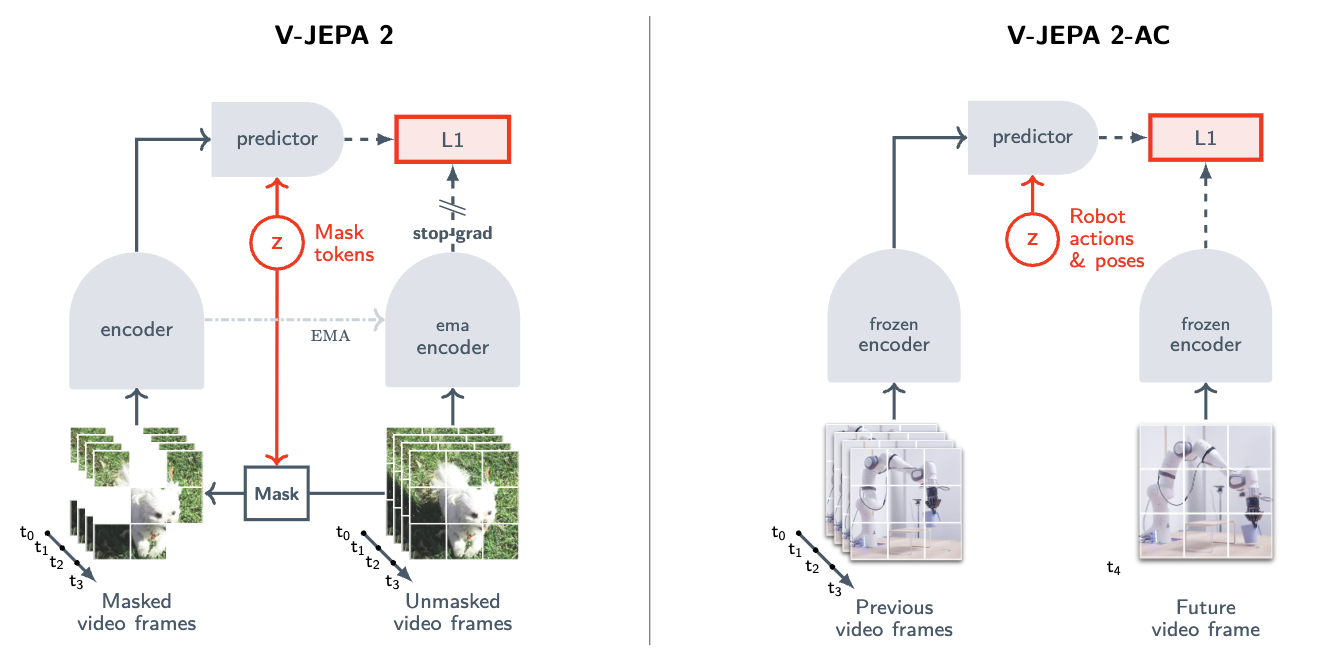
A market split: abstraction vs. pixel-perfect simulation
AMI Labs enters a rapidly expanding world model market, but with a distinctly different philosophy from its best-funded rivals. While LeCun's team bets on abstract embeddings for real-world decision making, competitors are scaling explicit generative simulation to unprecedented fidelity.

Where generative models offer interactive sandboxes for training AI, AMI Labs targets the intelligence layer, the decision-making machinery that runs at inference time. LeCun's team argues that predicting pixels remains too computationally expensive to ever power reliable, real-world autonomous systems.
Why this matters for cities, infrastructure and autonomy
For smart city technologists, robotics developers, and autonomous vehicle engineers, the architecture debate is not academic, it has direct consequences for what becomes buildable. LLMs consistently fail in the long tail of unpredictable physical events: a pedestrian stepping into the road at an unusual angle, an unfamiliar object on a warehouse floor, a robot navigating a space it has never seen.
An architecture that natively models the physical world from continuous experience could unlock AI systems robust enough for open environments , and efficient enough to run on edge devices and resource-constrained hardware, without requiring a data centre connection for every decision. AMI Labs has also committed to open-sourcing significant portions of its codebase, with the aim of building a wider research ecosystem around its approach.
Whether the industry's current momentum behind LLMs proves to be a foundation or a detour remains an open question. But with $1 billion, the world's most prominent critic of the prevailing paradigm is now in a position to find out.






