
Businesses
How Everyday Data Governance Actually Works in The AI Era: A Look At The Real Use Cases
18 Jun 2026

Data governance is an organisation’s framework of policies and processes for verifying data is accurate, secure, consistent, and used appropriately across an organisation. It helps organisations improve data quality, comply with regulations, protect sensitive information, and make better decisions based on trusted data.
Most governance strategies focus on protecting data where it is stored or processed—databases, applications, and controlled systems. These environments are secured, monitored, and audited.
However, once data leaves these systems—often in the form of files—it enters a far less controlled environment.
Research from major global research institutions such as Stanford AI Index shows that 24% of data breaches are caused by human error, often through simple actions like sending files to the wrong recipient or mishandling attachments.
In fact, misdirected emails have become a major risk category in their own right. A recent industry report found that 96% of organisations experienced data loss or exposure due to email errors within a single year, with many incidents going undetected internally. This directly supports the idea that organisations lack visibility into how data actually moves.
The problem is structural. When a file is sent system-to-system, including via email or using consumer-grade link-sharing, organisations often lose control over it. As cybersecurity research highlights, once data is removed from a secure system and shared externally, there is no guarantee it won’t be forwarded, stored insecurely, or accessed by unauthorised parties.
From a technical perspective, this issue is known as data exfiltration—the transfer of sensitive data from a secure environment to an external destination.
And the most common channels are surprisingly simple:
- Email attachments
- File-sharing platforms
- Cloud storage uploads
- USB or local downloads
These are all standard business tools, but they bypass central governance controls.
Once data moves through these channels, organisations lose:
- Visibility (who accessed it next)
- Control (whether it was forwarded or copied)
- Auditability (what actually happened over time)
This is why many data risks are not immediately identified. In fact, a large number of data exposures remain unnoticed for extended periods, precisely because organisations lack visibility into how data is being shared.

At the same time, the financial impact is significant. The average cost of a data breach is around $4.44 million globally.
Real-World Pressure Points: Where the Risk Becomes Visible
Financial Services
In financial institutions, data governance is critical to regulatory compliance. Yet even here, challenges persist. Banks frequently exchange sensitive information for reporting, client onboarding, and interbank operations.
For instance, during a client onboarding process of a global bank, a corporate client submits identity documents, financial records, and ownership structures, all of which are uploaded into a secure onboarding system. At this stage, everything is fully governed. But operational demands quickly change the nature of the workflow.
A compliance officer may download these documents to review them locally. To complete the process faster, they might forward selected files to a colleague in another region or share them with an external KYC provider.
In doing so, the same dataset is now duplicated across multiple environments—local desktops, email threads, and third-party systems. While the bank’s core system remains compliant, the data itself has moved beyond that controlled environment, and visibility is reduced.
Despite strong systems, many of these exchanges still rely on file-based processes that lack full visibility. This has led to repeated regulatory scrutiny, not because systems were insecure, but because data movement could not be fully tracked.
Public Sector and Smart Cities
In smart city ecosystems and public sector environments, data does not remain within a single system or organisation. It constantly moves between multiple entities, each with its own systems, priorities, and governance structures. This creates a highly interconnected environment where the value of data depends on how effectively it can be shared. However, this is also where one of the biggest governance challenges emerges.
Take transport data as an example. A modern city typically operates across multiple stakeholders: municipal transport authorities, private operators (such as bus or ride-sharing companies), infrastructure providers, and increasingly, technology platforms that manage traffic flow or mobility analytics. Each of these entities collects and processes its own data.
For the system to function efficiently, this data must be shared—real-time traffic updates, passenger volumes, route optimisation data, and incident reports all need to move across organisational boundaries. While each entity may maintain secure internal systems, the exchange of this data often relies on APIs, file transfers, dashboards, or even manual exports.
In many cases, there is no single, unified layer that governs how this data is shared end-to-end. As a result, visibility becomes fragmented, and accountability is difficult to establish if something goes wrong.
A similar pattern can be seen with citizen records. Public services such as healthcare, taxation, social welfare, and law enforcement often require access to overlapping datasets. For example, a citizen applying for a housing benefit may have their information accessed by multiple departments, each verifying different aspects such as income, identity, or eligibility. While the original data may reside in secure government databases, it is frequently extracted and shared between departments or external partners for processing. This can involve file transfers, document exchanges, or integration with third-party service providers.
Over time, multiple copies of the same data may exist across different systems, with limited visibility into who accessed it, how it was used, or whether it was further shared. The challenge is not the security of individual systems, but the lack of control over how data flows between them.

Similarly, governments and public bodies regularly share sensitive financial and operational data with external vendors, contractors, and consultants. This includes sensitive documents, pricing structures, project specifications, and compliance records. Although procurement platforms may be secure, the actual exchange of documents often extends beyond these platforms. Files may be emailed, downloaded for offline review, or shared with multiple stakeholders across organisations.
Each step introduces additional copies and potential exposure points. In large infrastructure projects involving multiple contractors and subcontractors, tracking the full lifecycle of a document becomes extremely difficult.
What connects all these examples is the fragmentation of the transfer layer. Core systems—databases, applications, and platforms—are typically well governed and secured.
However, the movement of data between these systems is handled through a mix of tools, processes, and human actions that are not centrally controlled. This creates blind spots in governance. Organisations may know where their data is stored, but they often do not have a complete view of how it moves, who interacts with it along the way, or where it ultimately ends up.
This fragmentation has practical consequences. It makes it harder to ensure compliance with data protection regulations, as organisations cannot always demonstrate full data lineage. It increases the risk of data leaks or misuse, especially when information is shared across multiple parties. It also reduces operational efficiency, as teams spend time reconciling different versions of data or verifying its accuracy.
Enterprises - Both Global and Local
In multinational organisations, the complexity is driven by scale and regulation. Large enterprises operate across multiple jurisdictions, each with its own legal and compliance requirements.
Data flows continuously between regional offices, internal teams, external vendors, and regulatory bodies. Companies such as IBM, Oracle, and OpenText have invested heavily in building sophisticated systems to manage this complexity.
These systems are designed to secure data within applications, enforce access controls, and maintain audit trails. However, the challenge does not lie within these systems—it emerges at the point where data is extracted and shared externally. When reports are downloaded, files are sent to partners, or data is exchanged across borders, it often moves through channels that are not governed with the same level of control.
Startups and high-growth companies, on the other hand, prioritise speed—rapid execution, seamless collaboration, and scalability. To enable this, they rely on flexible tools such as Dropbox, Google Drive, and Slack. These platforms make it easy to share information instantly across teams, locations, and partners. However, this flexibility often comes at the cost of control. Files are duplicated across folders, shared with multiple stakeholders, and modified in parallel without a clear record of ownership or version history. As the organisation scales, these informal practices become embedded into workflows, making it increasingly difficult to track how data is being used or where it resides.
The Missing Layer: Governance of Data Movement
We see a consistent pattern across industries—organisations examine how data is governed in practice. Governance is typically strong at the level of systems—databases, applications, and internal platforms are secured, access is controlled, and activity is logged. These environments are designed with compliance in mind, and they perform well within their defined boundaries.
However, the weakness appears when data moves between these systems, especially when it is exported as files and shared across teams, partners, or external entities. At this point, governance becomes fragmented because the controls that exist inside systems do not automatically extend to how data is transferred.
This is where many organisations are now shifting their focus towards managed file transfer (MFT). The key idea is not to introduce more policies, but to operationalise existing ones in the context of data movement.
Instead of allowing employees to use multiple informal channels such as email, cloud drives, or ad hoc file-sharing tools, MFT establishes a single, governed pathway for transferring sensitive data. This standardisation is critical because it removes variability in how data is handled and ensures that the same rules apply regardless of who is sending the data or where it is going. In practice, this is where MFT platforms such as Progress MOVEit are increasingly used to embed policy enforcement, encryption, and auditability directly into the transfer process—supporting governed, traceable data flows into AI and LLM-driven environments.
What makes this approach effective is the automation of control. Permissions, data classifications, encryption requirements, and destination rules are embedded directly into the transfer process.
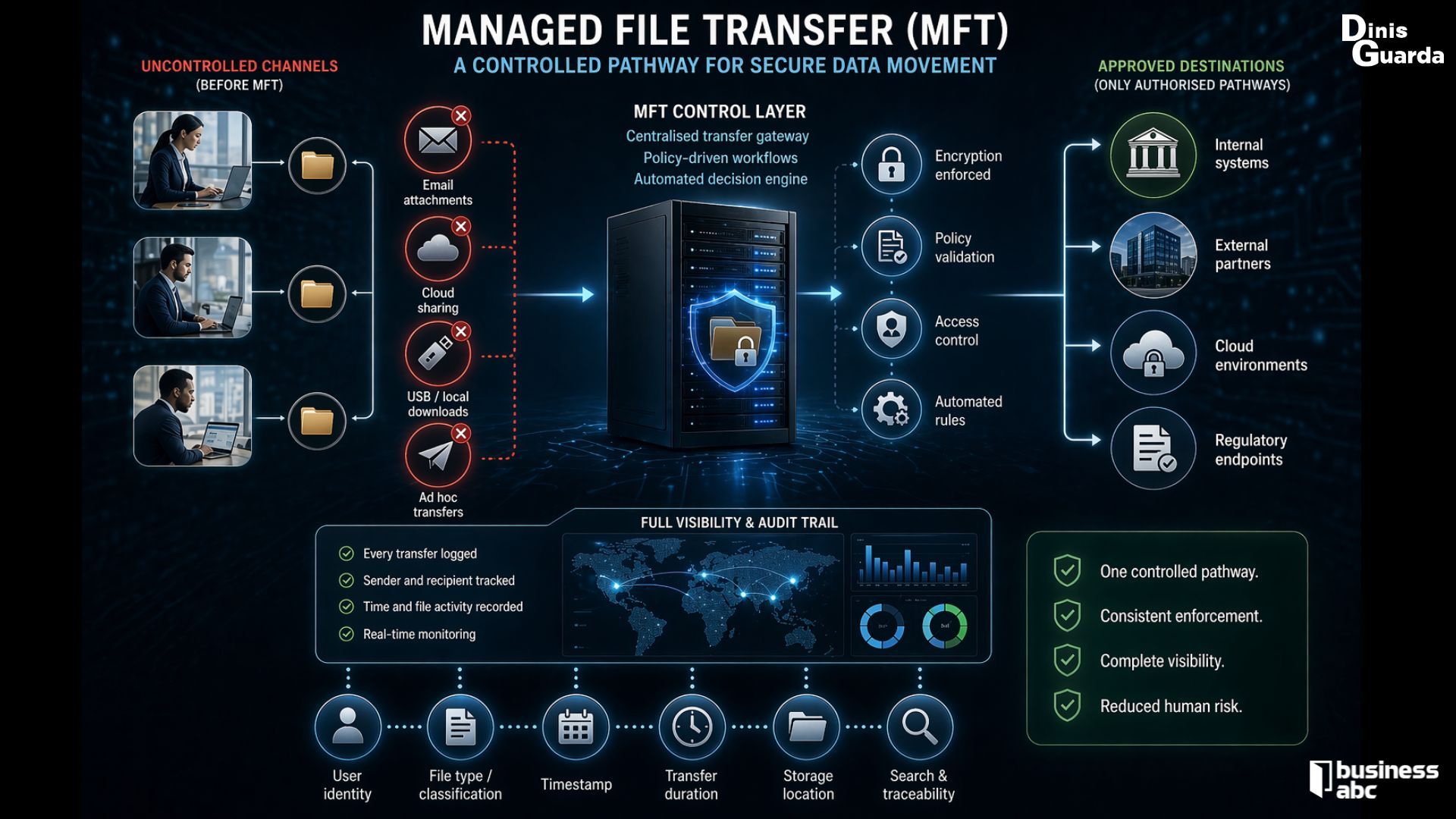
This means that decisions about what can be shared and with whom are no longer left to individual judgement under time pressure. The system enforces these rules consistently, reducing the risk of human error and ensuring compliance is maintained in real time.
Equally important is the visibility that MFT introduces. Every file transfer is recorded, including details such as the sender, recipient, transfer time, and the nature of the data being shared.
This creates a comprehensive audit trail that organisations can rely on when responding to regulatory queries, internal audits, or security incidents. Instead of trying to reconstruct events after the fact, leaders have immediate access to verifiable information about how data has moved across the organisation.
This shift fundamentally changes the nature of data governance. Rather than being a static framework defined by policies and documentation, governance becomes an active, operational capability embedded in everyday workflows.
The Question Every Organisation Must Answer
This brings us back to a simple but critical question:
If your organisation claims to take data governance seriously, can you actually see your data move?
The answer to this question will define not just compliance, but trust, efficiency, and long-term resilience in a data-driven economy. MFT might be the key to answering this question the way your business intends.
What is the shift in Data Governance for 2026?
It has moved from "passive compliance" to "active enablement." Governance now focuses on Machine-Readability. Data must not just be clean; it must be structured for LLM consumption.
Case Study: The World Bank’s GovTech initiative in Brazil used automated legal triage. By structuring judicial data into machine-readable formats, they reduced case backlogs by 40%.
Share

Dinis Guarda
Dinis Guarda is an author, entrepreneur, founder CEO of ztudium, Businessabc, citiesabc.com and Wisdomia.ai. Dinis is an AI leader, researcher and creator who has been building proprietary solutions based on technologies like digital twins, 3D, spatial computing, AR/VR/MR. Dinis is also an author of multiple books, including "4IR AI Blockchain Fintech IoT Reinventing a Nation" and others. Dinis has been collaborating with the likes of UN / UNITAR, UNESCO, European Space Agency, IBM, Siemens, Mastercard, and governments like USAID, and Malaysia Government to mention a few. He has been a guest lecturer at business schools such as Copenhagen Business School. Dinis is ranked as one of the most influential people and thought leaders in Thinkers360 / Rise Global’s The Artificial Intelligence Power 100, Top 10 Thought leaders in AI, smart cities, metaverse, blockchain, fintech.





