
business resources
Understanding Artificial Intelligence: Commonly Used Terms, Glossary, Acronyms & Terminology
21 Aug 2024

What is Artificial Intelligence (AI)? For a technology that holds a promise of reaching US$184.00bn in 2024, and a market volume of US$826.70bn by 2030, how to break the complex concepts, standardise definitions, serve as an educational tool, and keep users updated with the latest AI developments?
I understand the struggle you might be facing in finding the right resources to learn about Artificial Intelligence and its related terminology. As I struggled to gather information from various articles and documents, I took the initiative to compile my learning notes. I hope that sharing these notes will be helpful to you and others who are facing similar challenges.
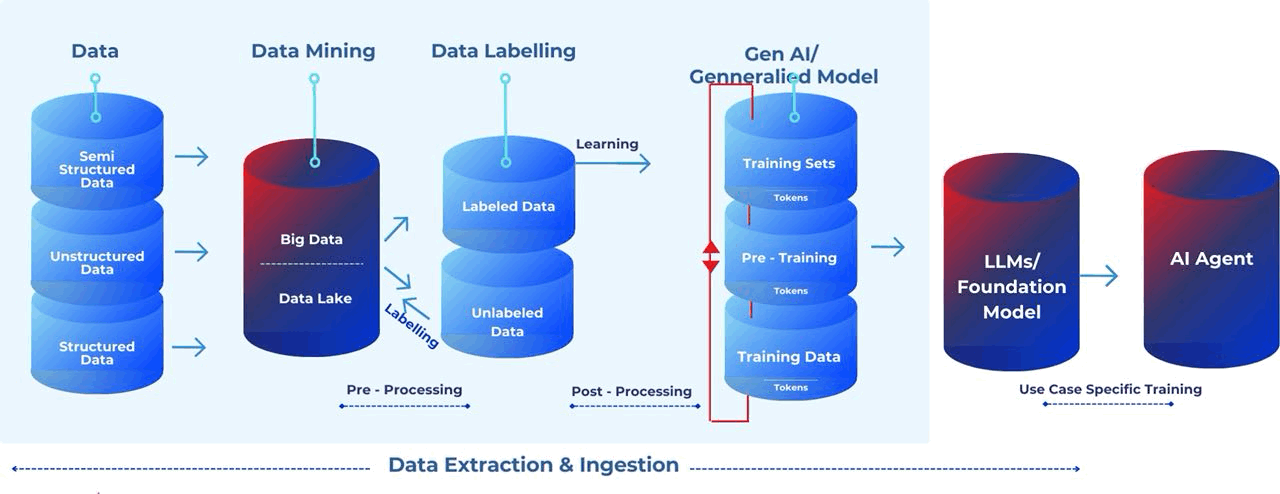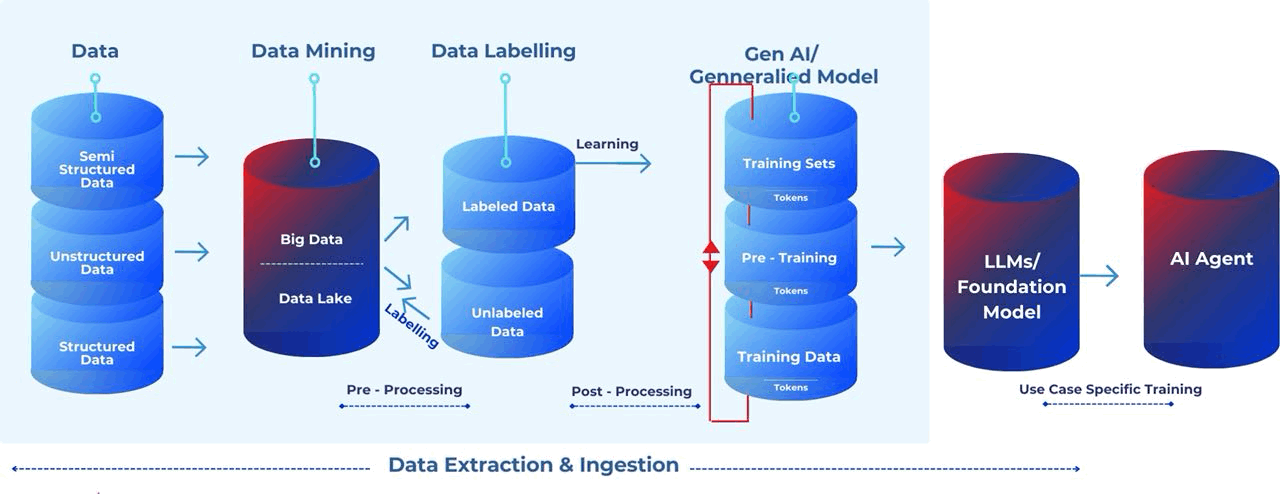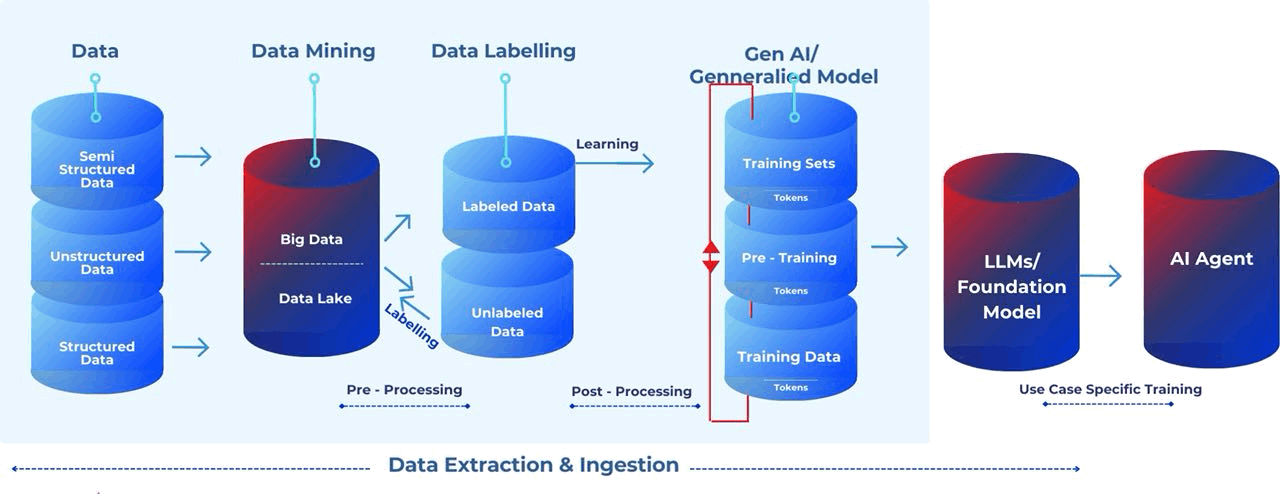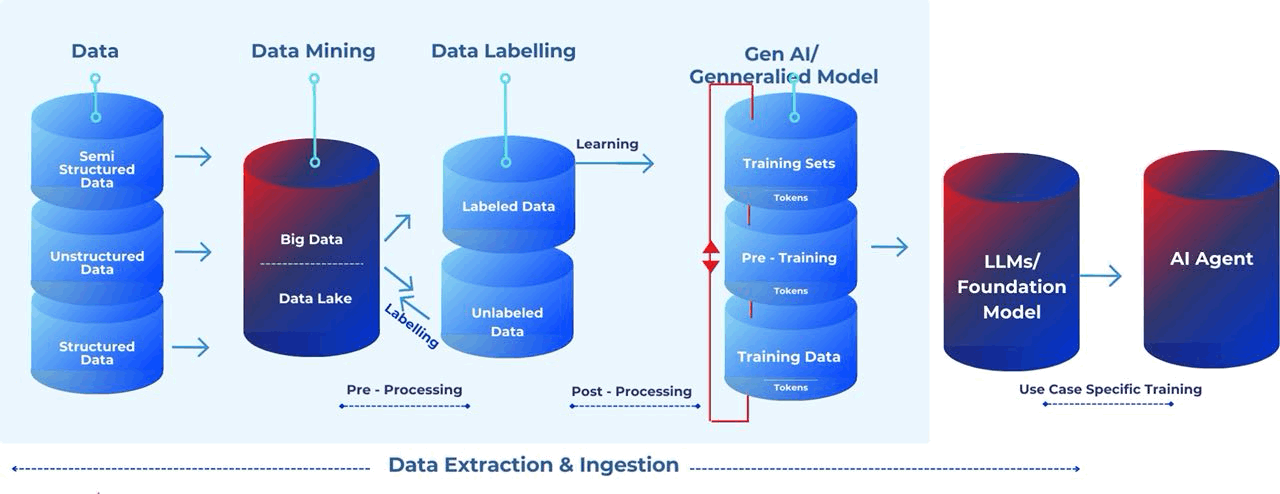
Here are the details and some architectural representations of the flow.
Disclaimer: I have gathered information from various web sources and worked to organise it coherently. I welcome any feedback to enhance the quality of the content.
Commonly Used Terms, Glossary, Acronym & Terminology in AI
Artificial Intelligence, Acronym: AI
Machines exhibit artificially created intelligence.
AI simulates human behaviour, such as speech and decision-making. With advancement, it has become more accessible and affordable, and many players are developing cost-effective solutions. AI means Artificial intelligence, automation, Learning, language, Natural or Neural, and Intelligence or Interface. AI enables machines to perform tasks requiring human intelligence, facilitated by machine learning and training data. AI aims to develop machines that think like humans, transforming our lives and work.
Subsets of AI
In artificial intelligence, classification is typically based on four primary types: reactive systems, limited memory systems, theory of mind systems, and self-aware systems. These classifications form the fundamental framework for categorising AI based on their functional capacities. Below are the commonly used types of AI.
Generative AI
It pertains to artificial intelligence systems capable of generating novel content such as text, images, music, or other data by leveraging learned patterns and structures within a specific dataset. For example: Generative AI creates synthetic video data to train machine learning models through video annotation when less real-world datasets are available. Such AI tools can also improve annotation quality by filling in the missing frames or generating comprehensive labels for moving objects, consequently making video-based AI applications more efficient. This capability empowers machines to express creativity and independently produce fresh, valuable outputs.
Conversational AI
The artificial intelligence that can understand and simulate human conversation, owes its existence to the dedicated work of developers. This technology enables natural language interactions through AI bots, leading to automation and personalised user experiences. Developers use conversational AI platforms to build chatbots and virtual assistants for various use cases, integrating them into messaging platforms, social media, SMS, and websites.
Artificial General Intelligence, Acronym: AGI, Synonym: Strong AI
AGI is a hypothetical AI system with human-like intelligence across various domains. Current AI technology is considered narrow artificial intelligence because it focuses on specific tasks rather than general adaptability. Achieving AGI has yet to be realised, and current approaches may not be feasible.
Humans AI Legacy versus AI Generative AI AGI
Narrow AI, Synonym: Weak AI
Narrow AI is specifically programmed to carry out particular tasks under predetermined conditions. Examples of narrow AI include virtual assistants like Siri, image recognition software, and self-driving cars. It is a system capable of solving problems based on its training and intended function.
Artificial Superintelligence, Acronym: ASI
The concept of Artificial Superintelligence postulates an advanced form of artificial intelligence that surpasses human cognitive abilities in all domains, encompassing creativity, general knowledge, and complex problem-solving. ASI represents the aspirational pinnacle of AI research, yet it remains speculative and has yet to be realised. This underscores the need for patience and understanding in its developmental process, reassuring the audience that progress is being made at a steady pace.
Knowledge Based AI, Acronym: KBAI
It is a subset of artificial intelligence that harnesses human expert knowledge to support decision making and problem solving. It uses structured knowledge to enable intelligent decision-making and problem solving by capturing and utilising human expertise. KBAI differs from newer AI approaches like deep learning, focusing on explicit representation and reasoning with structured knowledge. Researchers are exploring ways to integrate KBAI with other AI techniques and apply it to new domains.
AI Approaches
Responsible AI
Responsible AI is a collective responsibility aiming for fair, transparent, private, safe, secure, and compliant AI systems. Implementing responsible AI is crucial for professionals in AI, technology developers, policymakers, and business leaders, involving defining principles, training, governance, tool integration, and continuous monitoring. It's a practice that builds trust in AI, ensures regulation compliance, and prevents potential damage.
Explainable AI, Acronym: XAI, Synonym: Explainability AI
XAI aims to make AI systems' decisions understandable to humans, promoting transparency, interpretability, and accountability. Benefits include improved decision-making, faster optimization, increased trust, reduced bias, easier regulatory compliance, and better model performance monitoring. Techniques for XAI include feature importance analysis, LIME, SHAP, counterfactual explanations, decision trees, and rule extraction. XAI is crucial in high-stakes domains like healthcare, finance, criminal justice, and autonomous vehicles. Still, challenges include balancing model complexity and performance with explainability and developing meaningful explanations for different users. It aims to open the "black box" of AI systems, fostering trust and broader adoption of AI technologies.
Emotion AI, Synonym: Affective Computing
It involves developing algorithms to detect and analyse human emotions from text, audio, video, and physiological signals. It aims to improve human-machine interactions by enabling AI systems to authentically understand and respond to emotions. Emotion AI relies on natural language processing, voice emotion AI, facial movement analysis, and physiological signal processing. It is used in healthcare, marketing, education, customer service, gaming, and government, offering benefits like improved user experience and better decision-making. However, there are challenges related to bias, privacy concerns, and the complexity of emotions. The emotion recognition market is expected to grow significantly, with ongoing research aiming to improve the accuracy and ethical use of Emotion AI.
Symbolic AI
Symbolic AI continues to serve as a critical component within specific domains. It is increasingly important to develop neuro-symbolic AI systems through integration with neural approaches. Its value is particularly evident in tasks that rely on explicit reasoning and knowledge representation.
The ongoing integration of Symbolic AI with contemporary machine learning techniques further enhances its capabilities, allowing for more dynamic and effective problem-solving. This synergy enables Symbolic AI to evolve and adapt to the demands of the modern AI landscape.
Composite AI
AI integration combines different AI techniques and technologies, such as machine learning, natural language processing, computer vision, and knowledge graphs, to solve complex problems effectively. In manufacturing and robotics, computer vision is often extended with depth perception hardware a 3D camera adds spatial awareness to the system, enabling precise object recognition, dimensional measurement, and bin-picking automation. The aim is to leverage the strengths of different AI techniques in a complementary way to improve efficiency and solve a broader range of business problems. Composite AI, a comprehensive concept that can include various AI techniques and technologies, is designed for comprehensive problem-solving.
Hybrid AI
Hybrid AI, a versatile approach, involves the innovative combination of symbolic AI (rule-based systems) with non-symbolic AI (machine learning, deep learning). Its aim is to blend traditional rule-based approaches with modern data-driven techniques, offering a flexible and adaptive solution. Typically, it consists of two main components: symbolic and non-symbolic AI.
AI Component
Deep Learning, Acronym: DL
Deep learning, mirroring the human brain's information processing, is constructed on artificial neural networks with representation learning. Its ability to learn and classify concepts from images, text, or sound is significant, but it heavily relies on vast amounts of labelled training data and computing power. These factors play a crucial role in its success in tasks involving imagery, text, and speech.
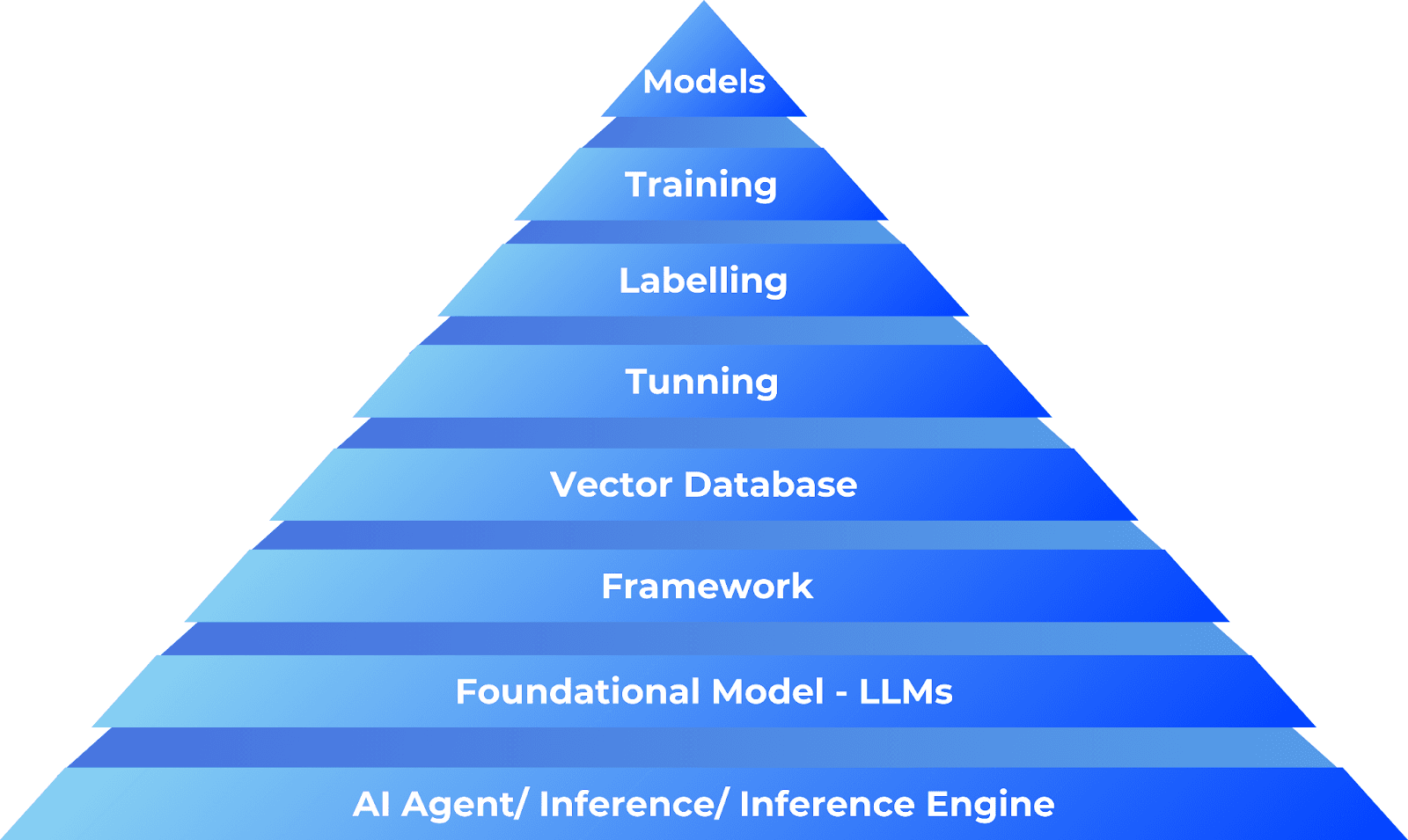
Generative pre-trained transformer, Acronym: GPT
An LLM used in ChatGPT and other AI applications pertains to textual data to learn natural language patterns before fine-tuning them for specific tasks.
Large Language Model, Acronym: LLM
Large language models, such as GPT -3 and GPT -4, developed by OpenAI, are versatile artificial intelligence systems. They process and comprehend natural language input, create responses, and perform a variety of language-related tasks. These tasks include translation, summarization, content creation, sentiment analysis, and more. Their versatility makes them a powerful tool in the field of artificial intelligence.
Small Language Models, Acronym: SLMs
Smaller models typically have fewer parameters, ranging from 500 million to 20 billion. They are optimised for specific tasks and are more efficient regarding computational resources than large language models (LLMs). These models can run on less powerful hardware, making them suitable for specialised tasks such as sentiment analysis, named entity recognition, and spam filtering, and they are cost-effective.
Natural Language Processing, Acronym: NLP
NLP is a branch of AI focused on teaching machines to understand, process, and generate human language. It enables tasks like machine translation, conversational agents, automatic speech recognition, and text analytics. However, due to natural language's complexity and nuance, NLP faces significant challenges and requires further development.
Natural Language Understanding, Acronym: NLU
NLU is a branch of AI that instructs computers to understand and interpret human language as we naturally use it. It goes beyond simple word recognition to analyse language's meaning, intent, and context. NLU is crucial for creating more advanced AI systems that can interact with humans more naturally and intuitively, thereby enhancing various applications from customer service to data analysis.
Machine Learning, Acronym: ML
Machine Learning is a subset of AI where systems learn from data to perform tasks without human intervention. ML algorithms improve with more data and make predictions without explicit programming. However, they may require help with bias, lack of explainability, and narrow use cases. ML needs constant monitoring and corrective action to function correctly.
Commonly Used Terms
It is represented here in the alphabetical order for easier access.
A
Accuracy: Accuracy is a scoring system in binary classification (i.e., determining if an answer or output is correct). It is calculated as (True Positives + True Negatives) / (True Positives + True Negatives + False Positives + False Negatives).
Actionable Intelligence: Information you can leverage to support decision making.
Algorithm: AI research is an ongoing and dynamic process that aims to ensure AI models remain helpful, safe, and reliable while aligned with human values and preferences. This process involves using algorithms for calculations, problem-solving, and data processing.
Algorithmic Bias: When an AI algorithm consistently produces unfair or biassed results, it is often due to biases in the training data.
Anaphora: In linguistics, an anaphora is a reference to a noun by way of a pronoun. For example, in the sentence, “While John didn’t like the appetisers, he enjoyed the entrée,” the word “he” is an anaphora.
Annotation: The process of tagging language data by identifying and flagging grammatical, semantic or phonetic elements in language data.
Artificial Neural Network: Acronym: ANN: A neural network is a computational model inspired by the human brain. It consists of interconnected nodes for tasks like image recognition and language processing.
Auto Classification: Machine learning, natural language processing (NLP), and other AI-guided techniques are used to automatically classify text more quickly, cost-effectively, and accurately.
Auto Complete: Auto-Complete, or predictive text, suggests queries based on the entered text and predicts the next word a user will type.
Automation: Automation is handling a process with machines or software so that less human input is needed.
Autonomous: Autonomous means carrying out tasks without human input and operating without human intervention.
B
Backpropagation, Synonym: Backward Propagation of Errors: Backpropagation is an algorithm used in supervised learning to train artificial neural networks. It is primarily used to calculate the gradient of the error function with respect to the network's weights, utilising the method of gradient descent to minimise errors and improve prediction accuracy.
Backward Chaining: Backward chaining is a reasoning method used in expert and rule-based systems. It starts with a goal and works logically backwards to determine what actions will achieve it by analysing if the preconditions for achieving the goal are met.
BERT: Acronym: Bidirectional Encoder Representation from Transformers: Google’s technology uses a large pre-trained model trained on unannotated data, which is then fine-tuned with a smaller task-specific dataset for NLP tasks.
Bias: The text you provided discusses bias in AI, its potential consequences, and ways to mitigate it. Recognising and addressing bias in AI is important to ensure fair and accurate decision-making.
Big data: Big data is a vast datasets that standard data-processing software can’t handle
Blind Prompting: Blind prompting is an AI technique in which the user gives a text-based prompt, and the artificial intelligence responds without using any additional context, such as images or knowledge bases. Blind prompting solely relies on pattern recognition from the model's training data. However, this can limit its comprehensive understanding and lead to incorrect assumptions.
Burstiness: Burstiness refers to uneven bursts in data transmission, impacting network performance due to sentence structure and length variation.
C
CAPTCHA: A test used online to ensure that the user is human
Cataphora: In linguistics, a cataphora is a reference placed before the noun it refers to. For example, in the sentence, Though he enjoyed the entrée, John didn’t like the appetisers; the word “he” is a cataphora.
Categorisation: Categorisation is a natural language processing function that assigns a category to a document.
Category: A category is a label assigned to a document in order to describe the content within said document.
Category Trees: Enables users to view, create, delete, and edit rule-based categories in a collection, also known as a taxonomy, arranged in a hierarchy.
Chatbot, Synonym: AI Chatbot: A chatbot is a computer program or AI-powered system designed to simulate conversation with human users through text or speech interactions. Chatbots use NLP and machine learning algorithms to understand user input, interpret intent, and generate appropriate responses. They can be deployed across various platforms, including websites, messaging apps, and voice assistants, to assist, answer questions, perform tasks, or facilitate transactions. Chatbots can range from simple rule-based systems that follow predefined scripts to more advanced AI-driven models capable of learning and adapting to user behaviour over time.
Chinese Room: The Chinese Room Argument, proposed by philosopher John Searle in 1980, challenges the claims of vital artificial intelligence (AI). It questions whether a computer running a program can genuinely understand language or possess a mind or consciousness, regardless of how intelligently it behaves.
Classification: Text categorisation techniques involve assigning predefined categories to open-ended text in order to organise, structure, and categorise various types of text, such as documents, medical records, emails, files, across different applications, and on the web or social media networks.
Clustering: Clustering is a machine-learning technique that groups similar data points into clusters based on their similarities.
Cognitive Computing: Cognitive computing uses AI and signal processing to simulate human thought processes, employing machine learning, reasoning, natural language processing, speech and vision recognition, and human-computer interaction to make AI more human-like.
Cognitive Map: A mental representation, also known as a mind palace, helps individuals acquire, encode, store, recall, and decode information about the relative locations and attributes of phenomena in their environment.
Completions: The output from a generative prompt.
Computational Linguistics: Computational linguistics is an interdisciplinary field concerned with the computational modelling of natural language.
Computational Semantics, Synonym: Semantic Technology: Computational semantics is the study of automating the construction and reasoning of meaning representations of natural language expressions.
Computer Vision: Computer vision enables machines to interpret visual information like the human visual system. Its goal is to develop algorithms that can extract, analyse, and interpret visual data for decision-making. It is also used in facial recognition systems.
Content: Individual containers of information, such as documents, can be combined to create training data or generated by Generative AI.
Content Enrichment: Applying advanced machine learning, artificial intelligence, and natural language processing automatically extracts meaningful information from text-based documents.
Controlled Vocabulary: A controlled vocabulary is a carefully selected set of words and phrases relevant to a particular application or industry. It includes characteristics that describe how the words are used in a shared language, their meanings concerning the subject matter, and more. Unlike a taxonomy, a controlled vocabulary comprises the specific words and phrases that should appear in a text.
Convolutional Neural Networks, Acronym: CNN: A deep learning class of neural networks with one or more layers is used for image recognition and processing.
Co-occurrence: A co-occurrence refers to the presence of different elements in the same document. It's used in business intelligence to recognise patterns and infer associations between concepts that are not naturally connected. For example, a name frequently mentioned in articles about startups successfully closing funding rounds could indicate that the investor is skilled at picking investments.
Corpus: The entire set of language data to be analysed. A corpus is a balanced collection of documents representing the content and distribution of topics for NLP solutions in production.
Custom Language Model, Synonym: Domain Language model: A model built specifically for an organisation or an industry, for example, Insurance.
D
Data Discovery: The process of uncovering data insights and delivering them to users when they need it.
Data Drift: Data Drift occurs when the distribution of the input data changes over time; this is also known as covariate shift.
Data Extraction: Data extraction is the process of collecting or retrieving disparate types of data from a variety of sources, many of which may be poorly organised or completely unstructured.
Data Ingestion: The process of obtaining disparate data from multiple sources, restructuring it, and importing it into a common format or repository to make it easy to utilise.
Data Labelling: A technique through which data is marked to make objects recognisable by machines. Information is added to various data types (text, audio, image and video) to create metadata used to train AI models.
Data Lake: A data lake stores large amounts of raw data in its native format until needed. It facilitates data access and analysis without the need to load it into a data warehouse, offering scalability and flexibility but requiring more data governance due to the unstructured nature of the data.
Data Mining: Data mining uses automated techniques and algorithms to uncover patterns, insights, and knowledge from large datasets. It allows machines to analyse data, discover hidden relationships, and identify trends. Decision trees predict outcomes by learning if-then decision rules from data features. Despite limitations, decision trees are widely used in machine learning.
Data Scarcity: The lack of data that could possibly satisfy the need of the system to increase the accuracy of predictive analytics.
Deepfake: Deepfake refers to AI-generated images and videos designed to look natural, often mimicking real human faces or voices.
Did You Mean, Acronym: DYM: Did You Mean is a natural language processing function used in search applications to detect typos in a query or suggest similar queries that could yield results in the search database.
Diffusion: A machine learning method involves adding random 'noise' to data - usually images, and training the AI model to recover the original image or create an altered version.
Disambiguation: It is the process of removing confusion around terms that express more than one meaning and can lead to different interpretations of the exact text string.
Domain Knowledge: The experience and expertise your organisation has acquired over time.
E
Edge Model: A model that includes data is typically placed outside centralised cloud data centres and closer to local devices or individuals, such as wearables and Internet of Things (IoT) sensors or actuators.
Embedding: The meaning of words, images, and audio is represented numerically to power neural networks for generative AI. A natural embedding is a list of numbers representing elements in a dataset. Embeddings reduce data sparsity and improve pattern recognition in AI algorithms.
Emergent behaviour, Synonym: Emergence: Emergence is a complex behaviour that can arise from basic processes, leading to new and unintended capabilities in AI models.
Entity: An entity is any noun, word, or phrase in a document that refers to a concept, person, object, abstract, or otherwise (e.g., car, Microsoft, New York City). The group also includes measurable elements (e.g., 200 pounds, 14 fl. oz.).
Environmental, Social, and Governance (ESG): An acronym initially used in business and government pertaining to enterprises’ societal impact and accountability; reporting in this area is governed by a set of binding and voluntary regulatory reporting.
ETL, Synonym: Entity Recognition, Extraction: Entity extraction is a natural language processing function that aims to identify relevant entities in a document.
Expert System: An expert system is a computer program designed to simulate the decision-making ability of a human expert. It helps solve complex problems using knowledge represented as if-then rules rather than conventional procedural programming code.
Extraction, Synonym: Keyphrase Extraction: It is a process of taking the essence of the text in documents, which can be described using multiple words.
Extractive Summarisation: Identifies the vital information in a text and organises the text segments to create a summary.
F
F-score, Synonym: F-measure, F1 measure: The F-score, a measure of precision and recall, is calculated using the formula: 2 x [(Precision x Recall) / (Precision + Recall)]. However, it's important to remember that using the F-score alone to evaluate predictive systems can be limiting, especially when an imbalance between precision and recall is present. This highlights the importance of considering other measures. For example, the F2 measure, which places more emphasis on recall, is suitable for critical applications that prioritise information retrieval over accuracy. Similarly, the F0.5 measure gives more weight to precision.
Few Shot Learning: Few-shot learning in AI uses small datasets and leverages previously learned concepts to generalise from very few examples, often using data augmentation and transfer learning when large labelled datasets are unavailable.
Fine-Tuned Model: A model focused on a specific context or category of information, such as a topic, industry or problem set
Forward Chaining: Forward chaining starts with known facts and uses inference rules to deduce new facts until reaching a goal. It simulates human reasoning from what is known to arrive at new conclusions. However, forward chaining can examine all possible rules at each step, so it tends to be inefficient compared to backward chaining, which works backwards from the goal.
Foundational Model: The baseline model is a starting point pre-trained on large datasets using self-supervised learning. It is the foundation for other applications or models, such as BERT, GPT-n, Llama, and DALL-E. These large, general-purpose foundation models have driven the generative AI revolution, and we rely on providers like OpenAI to create adaptable models due to the computing power and data required for training AI.
Framework: A framework is a basic conceptual structure used to solve broad problems. For example, machine learning frameworks provide tools and libraries that allow developers to build machine learning models faster and more efficiently.
Fuzzy Logic: Fuzzy logic is an approach to reasoning that deals with partial truths on a scale of 0 to 1, allowing for handling ambiguous or complex scenarios when clear binary logic doesn't work.
G
Generalised Model: A model that does not explicitly focus on specific use cases or information.
Generative Adversarial Network, Acronym: GAN: A GAN is a model comprising two neural networks, a generator and a discriminator, that compete against each other to generate realistic images.
Generative Summarisation, Synonym: Abstractive Summarisation: The LLM functionality condenses long-form text inputs such as chats, emails, reports, contracts, and policies into concise summaries for quick understanding. This is achieved through pre-trained language models and context comprehension, resulting in accurate and relevant summaries.
Grounding: Generative applications can connect the factual information in their outputs or completions to available sources such as documents or knowledge bases. This can also be done through direct citations or by searching for new links.
Guardrails: Policies and regulations are integrated into AI models to prevent them from causing harm, such as creating disturbing content and handling data responsibly. Guardrails are implemented to ensure that AI models' output stays within defined boundaries and to defend against issues like hallucinations, bias, and offensive outputs.
H
Hallucination: Fabricated data is false information presented as valid facts. These fabrications can also include made-up references or sources. Hallucinations occur when AI models generate nonsensical output. Language models, in particular, may produce factually incorrect, illogical, or fabricated information due to inadequate training data. These hallucinations underscore the limitations of current AI technology and emphasise the need for responsible development and oversight. Fabricated data can include inaccurate or misaligned references or sources presented as genuine.
Hashes: Hashes are generated from an algorithm to create a unique identifier for data. They allow for easy data comparison without revealing the contents and provide security. Hashed data is one-way, which means it cannot determine the original input from the hash.
Human in the loop, Acronym: HitL: "Human in the loop" AI involves human feedback and input, reducing risks from fully automated AI and leveraging the strengths of both humans and machines. However, more reliance on human input can introduce bias and limit the speed and scalability of an AI system.
Hyperparameters: These are adjustable model parameters tuned to obtain optimal performance of the model.
I
Intelligent Document Processing, Acronym: IDP, IDEP, Synonym: Intelligent Document Extraction and Processing: IDP entails automatically reading and converting unstructured and semi-structured data, identifying usable information, extracting it, and utilising it through automated processes. It is frequently a foundational technology for Robotic Process Automation (RPA) tasks.
Inferring: Inferring involves drawing logical conclusions from both facts and assumptions.
Inference: Inference is the process of using a trained model to make predictions. The system's inference capabilities were remarkable.
Inference Engine: It is a component of an expert system that applies logical rules to the knowledge base to deduce new information. They implement techniques for automated reasoning and help AI systems reach conclusions beyond their training data.
Insight Engines: An insight engine, cognitive search or enterprise knowledge discovery applies relevancy methods to describe, discover, organise, and analyse data. It combines search with AI capabilities to provide user information and machine data, aiming to deliver timely data that provides actionable intelligence.
K
Knowledge Engineering: A method for helping computers replicate human-like knowledge. Knowledge engineers build logic into knowledge-based systems by acquiring, modelling and integrating general or domain-specific knowledge into a model.
Knowledge Graph: It represents concepts connected by links to interpret a portion of reality. Each concept is linked to at least one other concept, and the quality of these connections can vary. Advanced knowledge graphs can have many properties attached to a node. They are machine-readable data structures representing knowledge about the physical and digital worlds and their relationships, following a graph model.
Knowledge Model: A process of creating a computer-interpretable model of knowledge or standards about a language, domain, or process(es). The knowledge is expressed in a data structure that enables it to be stored in a database and interpreted by software.
L
Labelled Data: Labelled data is data that has been tagged with one or more labels to provide context or meaning. It consists of raw data samples assigned informative tags to classify elements or outcomes.
Language Data: Language data is unstructured data made up of words. It is qualitative data, also known as text data, and refers to a language's written and spoken words.
Language Operations, Synonym: LangOps: The workflows and practices that support the training, creation, testing, production deployment and ongoing curation of language models and natural language solutions.
Lemma: The base form of a word represents all its inflected forms.
Lexicon: Knowledge of the possible meanings of words in their proper context is fundamental for processing text content with high precision.
Linked Data: Linked data is a way to connect and reference knowledge, such as linking concepts to their respective Wikipedia pages in a knowledge graph.
M
Machine Translation: Machine translation is the use of computer software to translate text or speech from one language to another without human involvement. It's a key application of artificial intelligence that has evolved significantly since the 1950s.
Metacontext, Synonym: MetaPrompt: It is a foundational instruction on how to train the model to behave.
Metadata: Data that describes or provides information about other data.
Model, Synonym: Machine Learning Model: A machine learning model is a computational representation of an algorithm that analyses text and makes predictions based on data.
Model Collapse: A potential issue with future AI models being trained on mostly AI-generated content leads to a decline in quality due to repetitive, uniform output, which could create a proliferation of low-quality content on the web used to train other AI models.
Model Drift: Model drift is the decay of models’ predictive power due to changes in real-world environments, such as changes in the digital environment and relationships between variables. An example is a model detecting spam based on email content, and then the spam content changes.
Model Parameter: These parameters are internal variables in the model determined using training data. They are necessary for making predictions and defining the model's capability and fit.
Morphological Analysis: Morphological analysis breaks down a problem into essential elements to better understand its use in problem-solving, linguistics, and biology.
Multimodal Models, Synonym: Modalities: Language models trained to understand multiple data types are more effective across various tasks.
Multitask Prompt Tuning, Acronym: MPT: MPS is an approach that sets up a template for a prompt representing a variable modified to enable repetitive prompts with only the variable changing.
Multimodal AI: Multimodal AI is an AI model capable of processing and outputting various forms of data, such as text, images, video, and voice.
N
Natural Language Generation, Acronym: NLG: NLG is a natural language generation which automatically converts structured data into human-readable language.
Natural Language Query, Acronym: NLQ: A natural language input containing only terms and phrases as they occur in spoken language, without non-language characters.
Natural Language Technology, Acronym: NLT: A linguistics, computer science, and AI subfield deals with NLP, NLU, and NLG.
Neural Machine Translation, Acronym: NMT: NMT utilises deep learning and neural networks to generate translations, providing enhanced fluency and accuracy compared to previous methods.
Neural Networks: Neural networks are machine-learning models inspired by the human brain. They use layers of nodes to uncover patterns through exposure to data. Although neural networks are suitable for complex patterns and predictions, they can be difficult for humans to interpret.
O
Ontology: An ontology is like a taxonomy but more complex, adding properties and connections between nodes. These properties are not standard and must be agreed upon by the classifier and the user.
Output: Output from an AI model depends on the input and the task it's trying to perform. If the training data is incomplete or biassed, the output will reflect that.
P
Paraphrasing Tool: A paraphrasing tool is an AI writing tool that automatically rephrases the input text.
Parameters: A set of numerical weights represents neural connections in an AI model, with values determined by training. Parameters are akin to knobs that control how a neural network processes input data and makes predictions.
Parsing: Parsing is identifying the single elements constituting a text and assigning them their logical and grammatical value.
Part of Speech Tagging, Synonym: Tagging, Acronym: POS: A Part-of-Speech tagger is an NLP function that identifies grammatical information about the elements of a sentence. Essential POS tagging labels every word by grammar type. More complex implementations can do tasks like grouping phrases, recognising clauses, building a dependency tree of a sentence, and assigning logical functions to words (e.g., subject, predicate, temporal adjunct, etc.). Tagging annotates data points with additional information, helping to organise and classify data. However, tagging relies on human input that can introduce bias and errors. Consistent tagging guidelines help improve quality.
Persona: In AI, personas help simulate more natural human conversations by allowing models to adopt different speaking styles and personalities. However, AI personas are superficial and not true emotional intelligence.
Plagiarism: Plagiarism is when someone uses the words or ideas of others without giving them proper credit.
Plugins: A software component or module that expands the functionality of an LLM system to cover a wide range of areas, including travel reservations, e-commerce, web browsing, and mathematical calculations.
Post Edit Machine Translation, Acronym: PEMT: The solution enables a translator to revise a document previously translated by machine, usually accomplished sentence by sentence using a specialised computer-assisted translation application.
Post Processing: Procedures may include various pruning routines, rule filtering, or knowledge integration, providing a symbolic filter for noisy and imprecise knowledge derived by an algorithm.
Pre Processing: Data preprocessing is an essential step in data mining and analysis. It involves converting raw data into a format that computers can quickly analyse. While analysing structured data is straightforward, unstructured data such as text and images must be cleaned and formatted before analysis.
Pre Training, Synonym: Pre Trained Model: A pre-trained model can be used as a starting point to create a fine-tuned contextualised version, applying transfer learning.
Precision: Precision is the percentage of correct results from a processed document. It applies to predictive AI systems like search and entity recognition. For example, if an application is supposed to find all dog breeds in a document and only returns five correct values, the precision is 100%.
Programming: Programming is the process of providing commands to a computer using programming code.
Prompt: A prompt is an instruction you give an AI program to get it to do or say something specific. Well-written prompts can help the AI's answer be valid, accurate, and not offensive. But even good prompts need a person to check the AI's work.
Prompt Chaining: An approach that uses multiple prompts to refine a request made by a model.
Prompt Engineering: The craft of designing and optimising user requests to an LLM or LLM-based chatbot to get the most effective result is often achieved through significant experimentation. Prompt engineering is the practice of experimenting with different prompts to get better outputs, often through approaches such as system prompting or few-shot prompting. It is the process of developing prompts for AI models to improve response relevancy and quality, requiring human oversight to avoid toxicity and uneven performance.
Q
Question & Answer, Synonym: Q&A: An AI technique enables users to ask questions in everyday language and receive accurate responses. With large language models, question-and-answer systems have evolved to allow users to ask questions using natural language and generate complete answers using Retrieval Augmented Generation approaches.
R
Random Forest: A supervised machine learning algorithm that constructs a "forest" by growing and combining multiple decision trees for both classification and regression problems in R and Python.
Recall: Recall is the percentage of correctly retrieved results based on an application's expected outcomes. It applies to various classes of predictive AI systems and can indicate the system's performance. For instance, if an application is designed to find all dog breeds in a document and only retrieves five correct values out of 10 mentioned, the system's recall is 50%.
Recurrent Neural Networks, Acronym: RNN: A commonly used neural network model in natural language processing and speech recognition allows utilising previous outputs as inputs.
Reinforcement Learning: Reinforcement learning is a type of machine learning that focuses on training agents to make sequential decisions in an environment to maximise a cumulative reward. Unlike supervised and unsupervised learning, reinforcement learning involves an agent interacting with an environment and learning from the consequences of its actions.
Reinforcement Learning With Human Feedback, Acronym: RLHF: RLHF, or reinforcement learning from human feedback, is used to fine-tune the GPT model by having users rate its responses. It allows the model to adapt and improve and is used to create ChatGPT from the underlying GPT model.
Relations: The identification of relationships is an advanced NLP function that presents information on how statement elements are related. For example, “John is Mary’s father” will report that John and Mary are connected, and this data point will carry a link property that labels the connection as “family” or “parent-child.”
Retrieval Augmented Generation, Acronym: RAG: Retrieval-augmented generation is an AI technique that enhances the quality of LLM-generated responses by incorporating external sources of knowledge. Implementing RAG in LLM-based question-answering systems offers benefits such as ensuring access to current and reliable facts, reducing hallucination rates, and providing source attribution to enhance user trust. RAG allows LLMs to access a knowledge base and incorporate contextual knowledge into their responses.
Return on Artificial Intelligence, Acronym: ROAI: Return on Artificial Intelligence is an abbreviation for return on investment on an AI-specific initiative or investment.
Rules-based Machine Translation, Acronym: RBMT: The 'Classical Approach' of machine translation uses linguistic rules and dictionaries to focus on grammar and syntax, giving words contextual meanings.
S
Sand Bagging: Sand-bagging means intentionally holding back to deceive others. With artificial intelligence, programmers can make a program seem less intelligent than it is to outsmart competitors or exceed customer expectations. It can be used to conceal an AI system's full capabilities.
Self Supervised Learning: Self-supervised training uses unlabeled data to train an AI model, generating supervisory signals for learning. It can utilise vast amounts of unlabeled data but has limitations for fine-tuning narrow tasks.
Semantics: Semantics is the study of the meaning of words and sentences, explaining how speakers understand sentences.
Semantic Network: A form of knowledge representation used in multiple natural language processing applications connects concepts through semantic relationships.
Semantic Search: Using natural language technologies improves user search capabilities by identifying concepts, entities, and relationships between words.
Semi Structured Data: Data that is structured in some way but does not follow the traditional tabular structure of databases. Attributes of the data may be different but can be grouped. For example, in an object database, data is represented as related objects (e.g., automobile make relates to model relates to trim level).
Semi Supervised Learning: Semi-supervised training in machine learning uses labelled and unlabeled data to achieve high accuracy with a small amount of human-labelled data. Unlabeled data must still be screened for bias, outliers, and other issues impacting model performance.
Sentiment: Sentiment is the general disposition expressed in a text.
Sentiment Analysis: Sentiment analysis is an NLP function that identifies sentiment in text and measures emotions, moods, and feelings. It helps companies gauge customer feedback from large volumes of text data. However, sentiment models still struggle with complex topics, sarcasm, and subtle shifts in tone that humans easily pick up on.
Similarity, Synonym: Correlation: Similarity in NLP retrieves documents similar to a given document. It offers a score to indicate closeness, but there are no standard ways to measure similarity, so it's often specific to an application.
Simple Knowledge Organisation System, Acronym: SKOS: SKOS is a standardised data model for organising knowledge systems, such as thesauri, classification schemes, subject heading systems, and taxonomies.
Specialised Corpora: A specialised corpus is a focused collection of data used to train AI and is tailored to specific industries or use cases such as banking, insurance, health, or legal documents.
Speech Analytics: Speech analytics uses speech recognition software to analyse recordings or live calls, identify words, and analyse audio patterns to detect emotions and stress in a speaker’s voice.
Speech Recognition, Synonym: Automatic Speech Recognition, Acronym: ASR: Computer speech recognition, or speech-to-text, enables a software program to process human speech into a written/text format.
Statistical Machine Translation, Acronym: SMT: SMT relies on statistical models from analysing large bilingual text corpora to generate translations.
Stochastic Parrot, Synonym Disparaging: AI models are often derogatorily referred to as "Stochastic Parrots," implying that their output merely mimics human speech without proper understanding.
Structured Data: Structured data is organised, neat, and easily understood by computers. It is stored in tables, fields, and relationships and follows a consistent order. A person or a computer program can easily access and use it.
Subject Action Object, Acronym: SAO: Subject-Action-Object is an NLP function that identifies the logical function of sentence parts, including the subject, action, object, and any adjuncts.
Supervised Learning: Supervised learning is a machine learning method in which models are trained using labelled data, pairing data with appropriate labels.
Swarm Intelligence, Acronym: SI: It studies collective behaviour in decentralised, self-organised, natural and artificial systems.
Symbolic Methodology: A symbolic methodology for NLP AI systems involves specific, narrow instructions to guarantee pattern recognition. Rule-based solutions are precise but may require more work than ML-based solutions depending on the application.
Syntax: The arrangement of words and phrases in a specific order creates meaning in language; changing the position of one word can alter the context and meaning.
T
Taxonomy: A taxonomy is a predetermined group of classes of a subset of knowledge, creating order and hierarchy among knowledge subsets. Companies use taxonomies to organise documents for easier search and retrieval by internal or external users.
Temperature: The text you provided explains how a parameter in natural language models controls the degree of randomness of the output and how temperature affects the creativity and accuracy of generated text.
Test Set: A test set is a collection of sample documents used to measure the accuracy of an ML system after training.
Text Analytics, Synonym: Text Analytics, Text Mining: Processing unstructured text involves deriving insights from large volumes of text, including classifying subjects, summarising, extracting key entities, and identifying sentiment.
Text Summarisation, Synonym: Summarisation: Text summarisation is the process of creating concise summaries of longer texts. It aims to save time and effort by conveying necessary information in a shorter format.
Thesauri: A language resource that describes relationships between words and phrases in a formalised form of natural language, it is used in text processing.
Tokens: A token is a unit of content corresponding to a word subset. Tokens can be words, numbers, or symbols. Breaking sentences into individual tokens helps AI programs understand grammar and word relationships, but tokens alone don't capture context or shades of meaning in the full text.
Training Data: The training data is the information used to teach an AI model. It consists of input data and their corresponding correct answers or labels. The data's quality, diversity, and size heavily impact the effectiveness of the resulting AI model.
Training Set: A training set is the pre-tagged sample data fed to an ML algorithm to learn about a problem, find patterns, and ultimately produce a model that can recognize those same patterns in future analyses.
Transfer Learning: A machine learning technique that utilises a pre-trained model and its knowledge as a starting point for new, specialised tasks.
Transferring: Transferring a machine learning model from one task to a related task can improve performance compared to training from scratch. However, fine-tuning is still necessary for the best results.
Transformer: A transformer is a deep learning architecture introduced in the paper "Attention Is All You Need" by researchers at Google in 2017. It is adequate for natural language processing (NLP) tasks and uses a self-attention mechanism to weigh the importance of different words in a sentence, regardless of their position. It is also an artificial neural network architecture used in training generative AI.
Treemap: Treemaps display large amounts of hierarchically structured (tree-structured) data. The visualisation space is divided into rectangles sized and arranged based on a quantitative variable. The levels in the treemap hierarchy are represented as rectangles containing other rectangles.
Tunable: Tunable is an AI model that can easily be configured to meet specific industry requirements, such as those in healthcare, oil and gas, departmental accounting, or human resources.
Tuning, Synonym: Model Tuning, Fine Tuning: Fine-tuning is adapting a pre-trained AI model to a specific task or domain by adjusting its parameters through additional training on new, task-specific data. This customisation generates accurate outcomes and insights.
Turing Test: The Turing Test is a method for evaluating a machine's capacity to demonstrate human-like intelligence. During the test, a person interacts with a computer and a human without knowing which is which. If the person cannot distinguish between the computer and the human based on their responses, the Turing Test is considered to be passed.
U
Unlabeled data: It refers to digital content not tagged and needs explicit tags or identifiers, making it more challenging to analyse and interpret than labelled data.
Unstructured data: Unstructured data refers to information without a clear format, such as text documents, images, audio files, and videos. It's difficult for computers to analyse due to its messy and disorganised nature. AI programs must process much unstructured data to find patterns and derive meaning. Unlike structured data, unstructured data doesn't follow a rigid model and is often more representative of real-world business information, like web pages, images, videos, documents, and audio.
Unsupervised Learning: Unsupervised learning is a machine learning approach where the model learns patterns in data without explicit labels or guidance. It discovers hidden patterns in data without using labelled data. For example, ChatGPT went through unsupervised learning and can converse about any topic as it wasn't trained on a specific topic.
V
Vector Database: A vector database is a specialised database used in AI and machine learning. It handles vector data, which are lists of numbers representing things like pictures, words, or sounds. These databases quickly find and compare these lists to find matches, aiding in tasks like suggesting products, recognising images, and understanding language.
Virtual Assistant, Synonym: AI Assistant: An AI Assistant, or virtual assistant, is an artificial intelligence-powered software program designed to assist users with tasks and activities using natural language interactions. These assistants understand spoken or typed commands, process them using natural language processing (NLP) algorithms, and provide information, perform tasks, or execute commands accordingly. They can do many functions, including answering questions, setting reminders, scheduling appointments, sending messages, making recommendations, providing navigation assistance, and controlling smart home devices.
W
Windowing: Windowing is a method that uses a portion of a document as metacontext or meta content.
Workflow: A workflow is a series of steps for an AI program to complete a task. Ensuring that AI works correctly is essential, but human oversight is also crucial.
Z
Zero Shot Extraction: Extracting data from text without prior training or annotations is a valuable skill. Triple or Triplet Relations, or Subject-Action-Object (SAO), is an advanced extraction technique. It identifies three elements (subject, predicate, and object) to store information.
Zero Shot Learning: Zero-shot learning is an AI technique where models perform tasks without direct training on those tasks. The models learn from related tasks to generalise to new tasks. However, they still need help with complex tasks requiring a large and diverse dataset for direct training.
Citation
https://www.scribbr.co.uk/using-ai-tools/glossary-of-ai-terms/
https://kindo.ai/blog/45-ai-terms-phrases-and-Acronym-to-know
https://www.englishclub.com/glossaries/ai-terms.php
https://library.etbi.ie/ai/glossary
https://faculty.ai/blog/your-essential-guide-to-genai-terminology-the-top-words-to-know/






